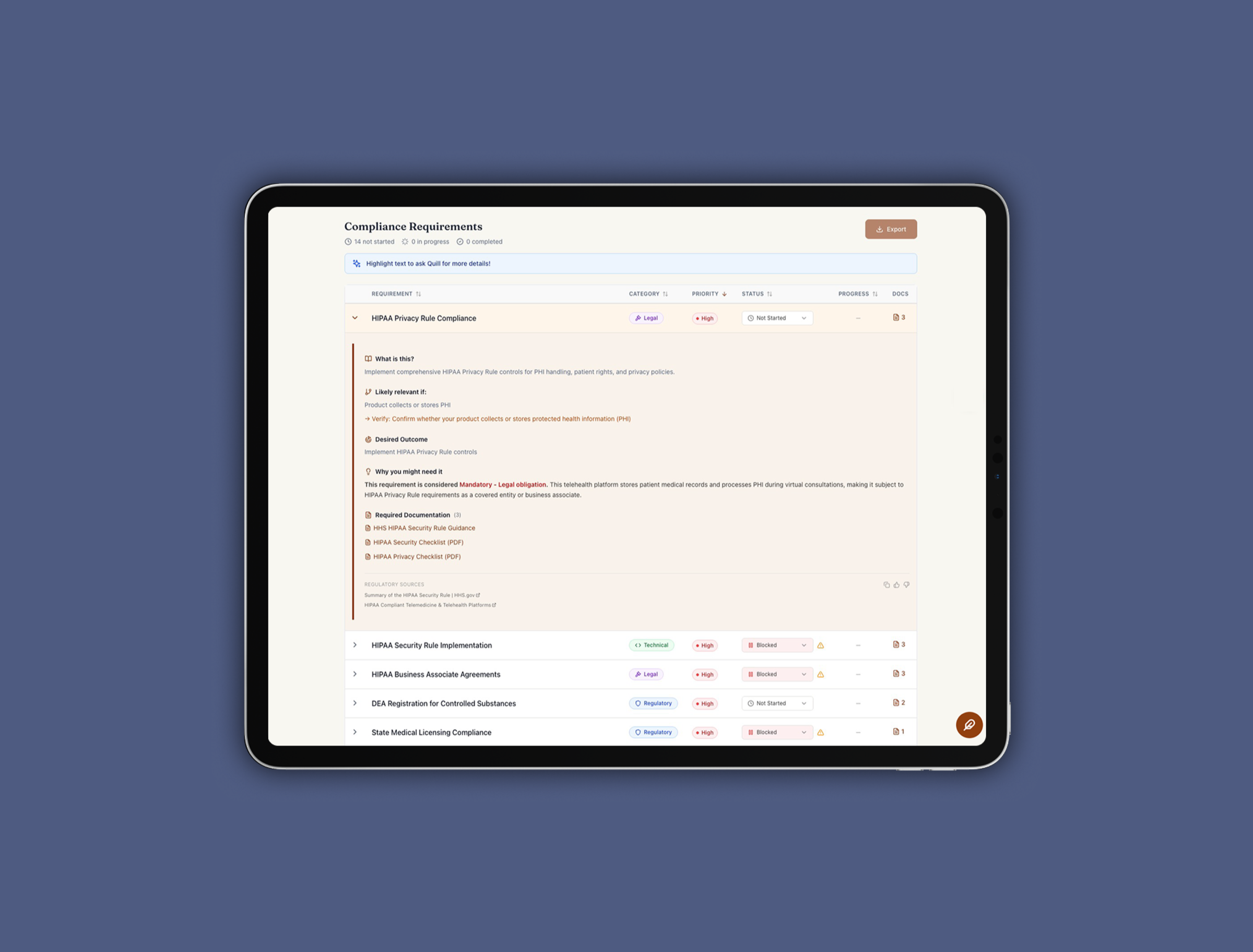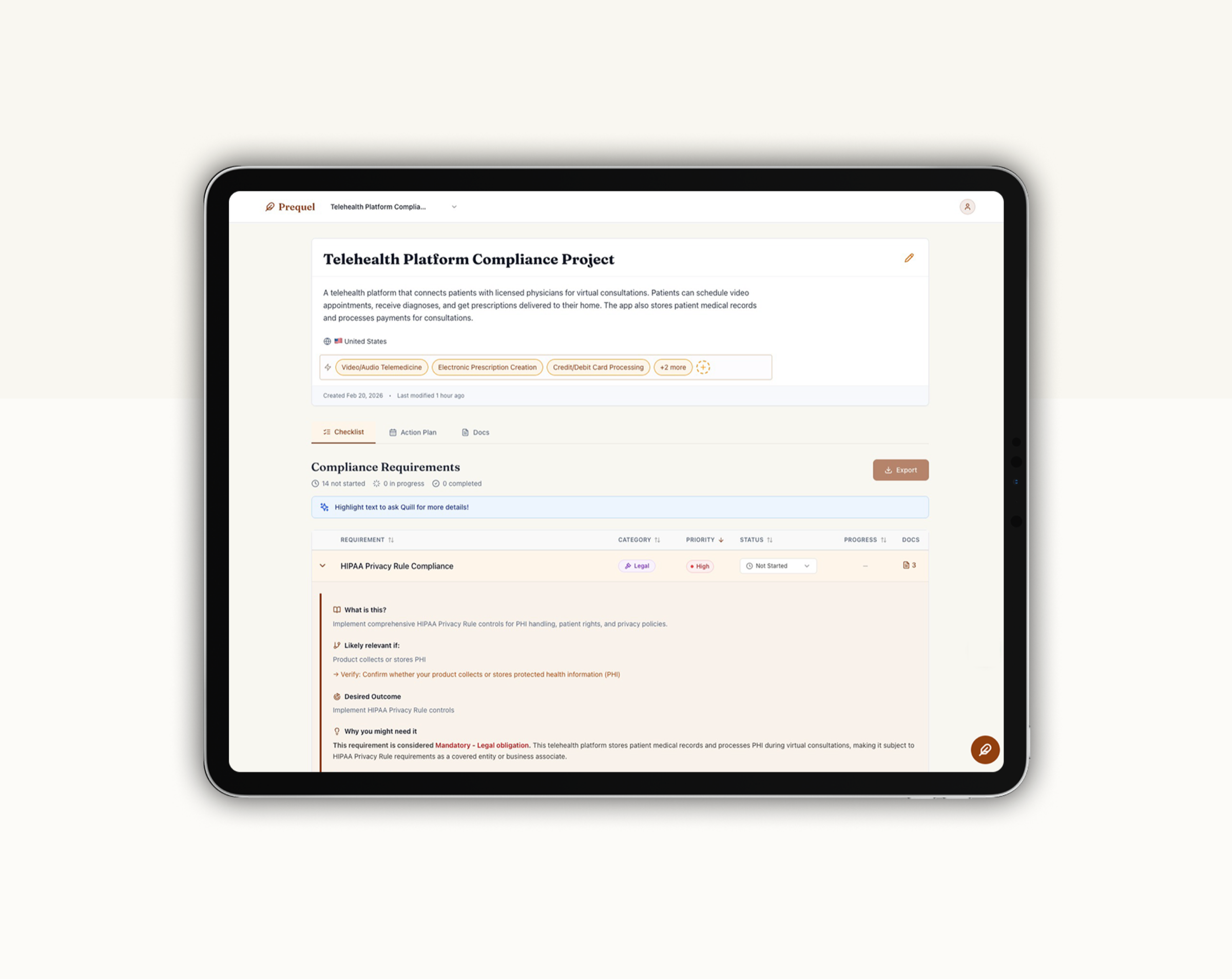
Overview
Three years of building healthcare products at Dentsply Sirona taught me something about compliance: even with a fully staffed Quality Assurance & Regulatory Affairs team, we as builders didn't always have what we needed. Navigating FDA 510(k) validation for the AI Aligner Fit ScanSee how we navigated FDA 510(k) for an AI diagnostic feature →, shipping through Dentsply Sirona's regulatory pipeline—each launch surfaced gaps. The QARA team's expertise had blind spots, especially around AI, where the regulatory landscape was evolving faster than anyone could keep up.
There were times when regulatory would flag a requirement mid-build: "if you want to build it out like this, you'll need to do xyz for compliance." Those things could take months, pushing back a launch we'd already committed to.
That experience was my discovery phase. I wasn't running formal user research yet, but I was living the problem every sprint.
Prequel is the product I built to solve that. It's an AI-powered compliance co-pilot that uses a multi-agent LLM system with RAG to surface regulatory and documentation requirements in plain English, before launch. I led the discovery, defined the product strategy, and built (okay, vibe-coded) the MVP.